DICOM XAという深遠にして難解なる世界への手がかり
DICOM-XAという動画フォーマットは、医療画像診断分野において1997年頃より全世界の医療現場・研究において用いられてきたものです。このDICOMフォーマットの制定により、全世界で統一されたフォーマットで画像情報を正確に伝達・保存が可能となったのです。しかしながら、その動画フォーマットであるDICOM-XAというものは、難解なデータ構造を持っています。
齋藤 滋は、2010年頃に、C/C++プログラミングの勉強のために自身でその動画再生プログラムを作成することを決意しました。しかし、それは困難と苦痛に満ちた試みでした。DICOM-XAは静止画のフォーマットである JPEGに基づいています。そして JPEGというフォーマットの根源にあるのは、ハフマン符号化というデータ欠損の無い圧縮です。なぜ、DICOM-XAが難解であるか? と問われれば、その多くは、肝腎のHuffmannフォーマットに関する明確な記述が JPEG仕様書にしか存在しないからであり、その JPEG独特の符号化をプログラミング言語で記載したものの解説は世の中にほとんど存在しないからでした。このような荒波の中、DICOM-XAの解読プログラム(=動画再生プログラム)を自分自身でフル・スクラッチで書くことに私は挑戦しまた。ここに、この齋藤 滋自身が歩んできた困難に満ちた長い戦いの記録を残します。
JPEGハフマン・テーブル - 解読実践(1)
2012年8月16日
実際のDICOM XAをbinary editorである Sterlingで解析しています。JPEG Tagである SOI (Start of Image) = 0xFFD8を探し、そこからDHT = 0xFFC4を探すと以下のバイト列が見つかりました。
FF D8 FF C4 00 1F 00 00 01 05
01 01 01 01 01 01 00 00 00 00
00 00 00 00 01 02 03 04 05 06
07 08 09 0A 0B FF C3
DHTの次に出てきた JPEG Tabは SOF3 = 0xFFC3です。これは、Start of Frame of Loslessというタグです。従って、この0xFFC3に引き続いて実際のシネ画像の一フレーム・データが存在するのです。それではこの実際のXA dataをもとにDHTの解読を実践してみましょう。そのように体と脳にしみこませればプログラムもスイスイ進む筈です。まずは、DHT部分のみ抽出します。
FF C4 00 1F 00 00 01 05 01 01
01 01 01 01 00 00 00 00 00 00
00 00 01 02 03 04 05 06 07 08
09 0A 0B
ということになります。これを前回のように、意味する部分で色分けしましょう。
FF C4 : DHTタグ
00 1F : 自分を含めて以降16 + 15 = 31 bytesがDHT
00 : 輝度DC成分の印です
00 01 05 01 01
01 01 01 01 00
00 00 00 00 00 00 : この16 bytesがそれぞれのbit数のハフマン符号個数
00 01 02 03 04 05
06 07 08 09 0A 0B : それぞれのハフマン符号に続くデータのビット数
ということになりますね。
JPEGハフマン・テーブル – 解読実践(2)
2012年8月16日
それでは前回のDHTを使用してハフマン符号を造りましょう
00 01 05 01 01
01 01 01 01 00
00 00 00 00 00 00
上記の16 bytesがそれぞれのbit数のハフマン符号個数でした。従って、
| ハフマン符号bit数 | その個数 | ハフマン符号 |
|---|---|---|
| 1 | 0 | NA |
| 2 | 1 | 00 |
| 3 | 5 | 010011100101110 |
| 4 | 1 | 1110 |
| 5 | 1 | 11110 |
| 6 | 1 | 111110 |
| 7 | 1 | 1111110 |
| 8 | 1 | 11111110 |
| 9 | 1 | 111111110 |
| 10 | 0 | NA |
| 11 | 0 | NA |
| 12 | 0 | NA |
| 13 | 0 | NA |
| 14 | 0 | NA |
| 15 | 0 | NA |
| 16 | 0 | NA |
ということになります。つまりこのDHTを用いて使われるハフマン符号は
00
010
011
100
101
110
1110
11110
111110
1111110
11111110
111111110
の12種類ということになります。この符号が、瞬時復元可能で、しかも一意的に復元可能であることに注目して下さい。
JPEGハフマン・テーブル – 解読実践(3)
2012年8月16日
さてさっき作成したハフマン符号は本当に一意で瞬時解読符号でしょうか? ハフマン木を作成してみます。さっきのハフマン符号は
00
010
011
100
101
110
1110
11110
111110
1111110
11111110
111111110
でした これに基づいて6bitsレベルまで作製したハフマン木は以下の通りです
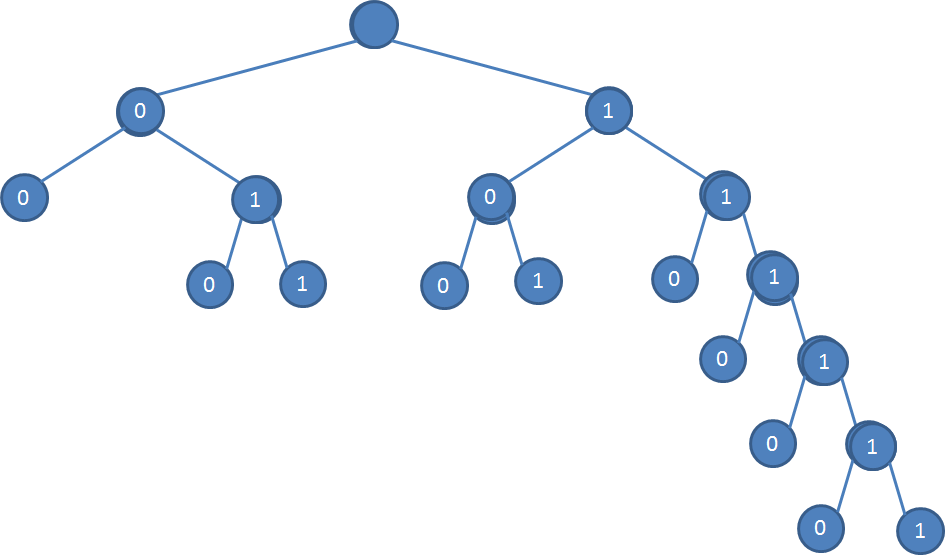
一意即時解読可能と分かります。
JPEGハフマン・テーブル – 解読実践(4)
2012年8月17日
さてさっきの一意瞬時復号符号であったハフマン符号はどのような規則に則って作成したでしょうか? それは簡単な規則なのです。
- ハフマン符号はビット0から開始する(これは取り決めなので文句言わないでね)
- 次のハフマン符号は+1したものとする
- ビット数を増加させるハフマン符号になる時には、これまでのハフマン符号に1を足してから、これを左に1 bitシフトして、最後のビットに0を追加する これによって、ビット数が1 bit増加したハフマン符号となる
これを繰り返すのみです。
あっ、もう朝カンファランスの時間
JPEGハフマン・テーブル – 解読実践(5)
2012年8月17日
それでは前回のアルゴリズムをC++で書きましょう まずは、何ビットのハフマン符号がいくつあるのか? つまり、例の青い部分の16 bytesを抱えるメモリーが必要ですね これを
unsigned char BITS[16];
で宣言します。そして、さっきの値を代入します
BITS[0] = 0x00; BITS[1] = 0x01; BITS[2] = 0x05; BITS[3] = 0x01;
BITS[4] = 0x01; BITS[5] = 0x01; BITS[6] = 0x01; BITS[7] = 0x01;
BITS[8] = 0x01; BITS[9] = 0x00; BITS[10] = 0x00; BITS[11] = 0x00;
BITS[12] = 0x00; BITS[13] = 0x00; BITS[14] = 0x00; BITS{15] = 0x00;
はい、これで準備整いました。
もちろん、できるだけコンピューターにやらせてしまおうとすれば、少しはプログラムらしく
for (int i=0; i<16; i++) {
BITS[i] = 0x00;
}
BITS[1] = 0x01; BITS[2] = 0x05; BITS[3] = 0x01;
BITS[4] = 0x01; BITS[5] = 0x01; BITS[6] = 0x01;
BITS[7] = 0x01; BITS[8] = 0x01;
としても良いわけですが・・・
JPEGハフマン・テーブル – 解読実践(6)
2012年8月17日
さて先ほど確保したBITS[]配列からどのようにしてハフマン符号を導けば良いでしょうか? さっき書いたアルゴリズムをそのままプログラムにすれば良い筈です
int code = 0; // ハフマン符号初期値は0である
for (int i=0; i<16; i++) { // これでBitS[]配列全体を走査する
for (int j=0; j<BITS[i]; j++) {
code+=1; // BITS[i]の値だけハフマン符号に1 bit足す
std::cout << code << std::endl; // できたハフマン符号を出力する
}
code <<= 1; // 次のビット数のハフマン符号のために、左に1 bitシフトする
}
これでどうでしょうか?
そんなに簡単に行く訳ありませんよね、デバッグするのも大変です。
JPEGハフマン・テーブル – 解読実践(7)
2012年8月17日
さて実際にコードをコンパイルする前に ハンド・デバッグをしてみます。
まず、外側の走査の最初 つまり i=0の時を見てみます。
さて先ほど確保したBITS[]配列からどのようにしてハフマン符号を導けば良いでしょうか? さっき書いたアルゴリズムをそのままプログラムにすれば良い筈です
int code = 0; // ハフマン符号初期値は0である
for (int i=0; i<16; i++) { // これでBitS[]配列全体を走査する
for (int j=0; j<BITS[i]; j++) {
code+=1; // BITS[i]の値x;だけハフマン符号に1 bit足す
std::cout << code << std::endl; // できたハフマン符号を出力する
}
code <<= 1; // 次のビット数のハフマン符号のために、左に1 bitシフトする
}
これでどうでしょうか?
そんなに簡単に行く訳ありませんよね、デバッグするのも大変です。
ですから、内側のループつまり、jをカウンターとするループですが、BITS[i]は0x00でしたので、このループは回りません。従って、code+=1の命令は走りませんので、codeは0のままです。
そして、内側のループを出て、外側のループに入りますので、ここではcodeは 1 bit左シフトしますので、0x00となります。しかし問題は、このハフマン符号が 2 bitsのものだ、ということをどこかに記録せねばなりませんね。そうでないと、integer型の0x00は何ビットzeroが並んでいるのか誰にも分かりません。
そういうことで、このハンド・デバッグで、もう一つ何ビット長のハフマン符号であるかを記録する配列が必要、ということが分かりました。これは重要な進歩です。
JPEGハフマン・テーブル – 解読実践(8)
2012年8月17日
さあ大分進みましたね。まあ自分で思っているだけで、分かっている方々から見れば、「なあにやってるの? 未だそんなレベルなの?」でしょうが、いいんだ いいんだ
ここまでのことを纏めましょう。何しろもう一つ配列が必要だと分かりました。この配列もバイト配列で良いでしょう。その個数はハフマン符号語の個数ですから これは動的に確保せねばならない、ということになります。何故ならばハフマン符号語の数は、それぞれのハフマン・テーブルが変化するからです。あるいは大きめの配列を確保してメモリーを無駄遣いしても良いのですが、なんかなあ スマートじゃないなあ 僕の美学に反するなあ
という訳で、BITS[]も動的に確保することにします。これなんかは何時でも16個と決まっているので、それも変な話しですが・・・
という訳で、まずはこれらの作業領域の確保部分です
typedef unsigned char u_char; // これ以降長いので
// u_charという型を定義した
u_char * BITS = new u_char[16]; // バイト配列16個確保
for (int i=0; i<16; i++) { // データをセット
BITS[i] = 0x00;
}
BITS[1] = 0x01; BITS[2] = 0x05; BITS[3] = 0x01;
BITS[4] = 0x01; BITS[5] = 0x01; BITS[6] = 0x01;
BITS[7] = 0x01; BITS[8] = 0x01;
int sum=0;
for (int i=0; i<16; i++) {
sum += BITS[i]; // これでハフマン符号語の総数を求める
}
u_char * HUFFBITS = new u_char[sum];
// これでハフマン符号語長を保持する
// HUFFBITS配列が動的に確保された
int * HUFFCODE = new int[sum];
// ついでにハフマン符号語を入れる
// 配列HUFFCODEも動的に確保する
さあこれで良いかな?
何しろ C++使うの2年ぶりなので、すっかり文法を忘れています。まあ、コンパイルすれば誤りは分かるのでまたその時点で修正しましょう。
JPEGハフマン・テーブル – 解読実践(9)
2012年8月18日
大事なデータを忘れていました。最終的に対応するハフマン符号が意味するのは、その後に続く、つまり緑の部分でした この部分は、ハフマン符号語に続く何ビットがデータを表しているかを示します この部分も配列に入れる必要がありますね そこで追加です
int * HUFFVAL = new int[sum];
うん? 待てよ ということになると動的に確保する三つの配列 つまり HUFFBITS, HUFFCODE, HUFFVALは同じインデックス同志が意味を有する、ということになりますね、だとすれば、これら三つで意味を有するので構造体として一つにまとめる方が論理的に分かりやすいですよね、そこで構造体を定義します さらには、その構造体にインデックス最大値を保持する変数も含めることにしましょう またこれまではハフマン符号語長を保持する配列 HUFFBITSをバイトで確保していましたが、これは最大 16bitsあるのでintにせねばなりませんでした そこで
struct HUFFDECODE {
int numHuffElement; // ハフマン符号語の総数
int * HUFFBITS; // ハフマン符号語長
int * HUFFCODE; // ハフマン符号
int * HUFFVAL; // ハフマン符号が表すデータ
}
このような構造体を定義しました ふーっ、道は遠い
そうそう昨日は京都で夜講演があり、久しぶりに京都の町に繰り出しました。とても暑く、また一昨日は大文字送り火だったので、ものすごい混雑でした。
JPEGハフマン・テーブル – 解読実践(10)
2012年8月18日
さあここまでで準備できたので、少しはプログラムらしくしてみます
struct HUFFDECODE {
int numHuffElement; // ハフマン符号語の総数
int * HUFFBITS; // ハフマン符号語長
int * HUFFCODE; // ハフマン符号
int * HUFFVAL; // ハフマン符号が表すデータ
}
typedef unsigned char u_char; // 短縮形の定義
u_char BITS[16]; // 何ビットのハフマン符号が存在するか?
// データのセット 実際のプログラムではファイルから読み込む
for (int i=0; i<16; i++) { // データをセット
BITS[i] = 0x00;
}
BITS[1] = 0x01; BITS[2] = 0x05; BITS[3] = 0x01;
BITS[4] = 0x01; BITS[5] = 0x01; BITS[6] = 0x01;
BITS[7] = 0x01; BITS[8] = 0x01;
int sum=0;
for (int i=0; i<16; i++) {
sum += BITS[i]; // これでハフマン符号語の総数を求める
}
//
// ハフマンテーブル領域の動的確保
ああダメだ 挫折 少し頭を冷やしましょう
JPEGハフマン・テーブル – 解読実践(11)
2012年8月18日
何か C++の言語仕様に対して根本的に間違っていたような気がします。Webにアクセスしてもう一度考え直しました。前回のプログラム・パーツを以下のように書き換えました
typedef unsigned char u_char; // u_char型の宣言
typedef struct {
int HuffBit; // ハフマン符号のビット長
int HuffCode; // ハフマン符号
int HuffVal; // ハフマン符号の意味する値
} HUFFTAB; // これでHUFFTABという型を宣言した
u_char BITS[16]; // それぞれのビット長のハフマン符号がいくつあるか
// 常に16バイトなので静的に配列確保した
// データのセット 実際のプログラムではファイルから読み込む
for (int i=0; i<16; i++) { // データをセット
BITS[i] = 0x00;
}
BITS[1] = 0x01; BITS[2] = 0x05; BITS[3] = 0x01;
BITS[4] = 0x01; BITS[5] = 0x01; BITS[6] = 0x01;
BITS[7] = 0x01; BITS[8] = 0x01;
int huffElementNo = 0;
for (int i=0; i<16; i++) {
huffElementNo += BITS[i]; // これでハフマン符号語の総数を求める
}
//
// ハフマンテーブル領域の動的確保
HUFFTAB *ht = new HUFFTAB[huffElementNo];
// これでハフマン表の領域が確保された
これで良いのですよ 今度は間違いない、と確信しています
JPEGハフマン・テーブル – 解読実践(12)
2012年8月18日
物事には順序が必要です。気が付けば、デバグをするためねにはプログラムを書かねばならない、そのように思いました。
どういう仕様が必要か? ハフマン符号と、その長さを入力すれば、左詰めで1と0のハフマン符号が出力される、それが必要です。
艱難辛苦の末、以下のプログラムを書きました 如何にも単純、しかし作動します。ビット演算の魔術師にかかれば、もっと高速で効率の良いプログラムを書けるでしょう。そんなことわかっています。でも、まずは確実に動くものを造り、それから改良するのです。何しろ僕は、改良が得意な日本人の一人なのですから・・・
void outbit(const int& hc, const int& hb) {
// 16 bitsの長さ hbのハフマン符号 hcを左詰めで出力する
int mask = 0x01;
for (int i=hb; i>0; i--) {
mask <<= (i - 1);
if ((mask & hc) != 0) {
std::cout << 1;
} else {
std::cout << 0;
}
mask = 0x01;
}
std::cout << std::endl;
};
JPEGハフマン・テーブル – 解読実践(13)
2012年8月18日
できた できた できたのだ
Windows7 VisutalStudio 2010でC++でテストしました
// JPEG_Analysis.cpp : programmed by S. SAITO, MD, FACC, FSCAI, FJCC
// created at 5:00AM on August 20th Monday 2012
//
#include "stdafx.h"
#include
typedef unsigned char u_char; // u_char型の宣言
typedef struct {
int HuffBit; // ハフマン符号のビット長
int HuffCode; // ハフマン符号
int HuffVal; // ハフマン符号の意味する値
} HUFFTAB; // これでHUFFTABという型を宣言した
void outbit(const int& hc, const int& hb) {
// 16 bitsの長さ hbのハフマン符号 hcを左詰めで出力する
int mask = 0x0001;
for (int i=hb; i>0; i--) {
mask <<= (i-1);
if ((mask & hc) != 0) {
std::cout << '1';
} else {
std::cout << '0';
}
mask = 0x0001;
}
std::cout << std::endl;
};
int _tmain(int argc, _TCHAR* argv[])
{
u_char BITS[16]; // それぞれのビット長のハフマン符号がいくつあるか
// 常に16バイトなので静的に配列確保した
// データのセット 実際のプログラムではファイルから読み込む
for (int i=0; i<16; i++) { // データをセット
BITS[i] = 0x00;
}
BITS[1] = 0x01; BITS[2] = 0x05; BITS[3] = 0x01;
BITS[4] = 0x01; BITS[5] = 0x01; BITS[6] = 0x01;
BITS[7] = 0x01; BITS[8] = 0x01;
int huffElementNo = 0;
for (int i=0; i<16; i++) {
huffElementNo += BITS[i]; // これでハフマン符号語の総数を求める
}
//
// ハフマンテーブル領域の動的確保
HUFFTAB *ht = new HUFFTAB[huffElementNo];
// これでハフマン表の領域が確保された
int code = 0; // ハフマン符号初期値は0である
int huffElement = 0; // 配列のカウンター
for (int i=0; i<16; i++) { // これでBitS[]配列全体を走査する
for (int j=0; j < BITS[i]; j++) {
ht[huffElement].HuffBit = i+1;
ht[huffElement].HuffCode = code;
ht[huffElement].HuffVal = 0; // とりあえずdummyで0を入れておく
huffElement++;
code+=1; // 次のハフマン符号のために1 bit足す
}
code <<= 1; // 次のビット数のハフマン符号のために、左に1 bitシフトする
}
for (int i=0; i < huffElementNo; i++) {
std::cout << "Bit = " << ht[i].HuffBit << " ::: Code = " << " ";
outbit(ht[i].HuffCode, ht[i].HuffBit);
}
char ch = NULL;
while (ch != 'e') {
std::cin >> ch;
}
return 0;
}
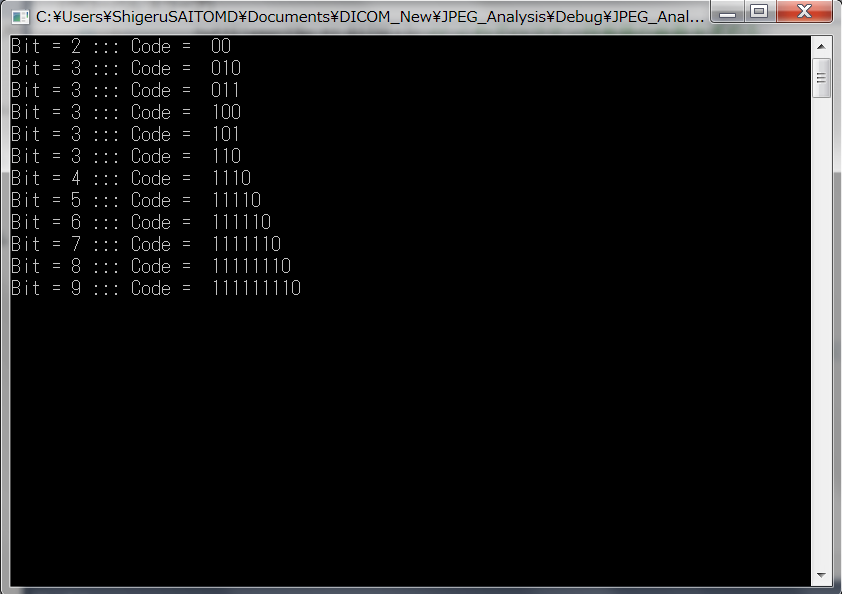
結果出力は以下の通り